Intro to Python Tutorial
Intro to Python Programming
This is a notebook from a workshop I gave to Biology Graduate students at McGill University. The tutorial was intended for people who are completely new to Python and lays down the basics for Python in data science. Future tutorials will include topics from Pandas, scikit-learn, numpy and seaborn.
By the end of this tutorial you will be comfortable with all the Python basics, and you will go through an example of analyzing and visualizing a real dataset. In this case, you will work with a real dataset of historical baby names in the US and build a model to identify ‘hipster names’.
I hope you enjoy this notebook. You can find the original files here. There, you will find a version of the notebook with the suffix _work.ipynb. You can use that notebook for a more interactive experience by doing some ‘fill in the blanks’ work.
Recommended setup: I suggest you install Anaconda which contains the Python interpreter as well as the Jupyter notebook environment. It is also very useful for installing and managing libraries. Check out this simple guide to getting started with the Jupyter notebook. I also highly recommend running Anaconda with Python 3.5+.
If you have any questions or comments please let me know!
C.
Why Python?
- It’s a full and general purpose programming language.
- Clean and elegant, easy to learn and be productive.
- It’s free and open source (you can always know exactly what your code is doing)!
- Huge community.
- Very popular for scientific programming and data science.
Projects using Python:
- YouTube
- NASA
- Dropbox
- Many more.
Workshop Objectives
- To give you the essential Python tools so that you can start to apply it to help you in your own work or research!
Programming Basics
We can boil down programming into two main ‘entities’: Data and Operations. In a program, we have some information, or data, and we perform some operations on it to produce the desired output. So let’s see how these two are represented in Python.
Data
As you can imagine, data can come in several forms and be packaged in many ways. The fundamental Python data types that we will cover here are the following: integers, floats, booleans, and strings. We can store the values of these different types in what we call ‘variables’. You can just think of them as containers with a name (no spaces or special characters!) that have a piece of data. Below are some examples of how we can work with these data types.
Primitives
# this is a comment. anything that follows a '#' symbol in Python is ignored by the interpeter
# here are two ways we can represent numbers
#integers a.k.a int
x = 4 #here we store the integer value of 4 in the variable x
y = 2
#floating point numbers
a = 0.5
b = 0.1
# strings are sequences of characters. they are always contained in single or double quotes
s = "Hello, world."
#booleans are data types that can take on only the values 'True' or 'False':
n = False
m = True
#finally, we have the 'None' type which is basically nothing, it's like an empty variable
t = None
## so now what we've done is store some values in some variables. how can we see what those values are? print!
print(x)
print(y)
print(a, b)
print(s)
print(n)
print(m)
print(t)
4
2
0.5 0.1
Hello, world.
False
True
None
#another useful thing is type-casting where we can convert some types into other types.
x = 5.0
y = "5.0"
#converts a floating point number to an integer
print(int(x))
#converts the string "5.0" into a numeric value
print(float(x))
5
5.0
# we can do some basic operations on these data types
print(4 + 4) #add or subtract two integers
print(4/5) # divide
8
0.8
5
Hello, world. How are you?
# we can assign the value of a variable back to itself.
x = x + 1
print(x)
6
#we can 'concatenate' two strings
print(s + " How are you?")
Hello, world. How are you?
Data structures
Now that we have a better idea of the types of information Python handles. We would like to scale things up and be able to store the data in a way as to be able to easily handle many values at once.
Lists
A list is simply an ordered collection of values.
# This is a list:
l = [1, 2, 3, 4]
# we can access each element in a list with its index (starting from 0)
print(l)
print(l[0]) #prints the first element in the list
print(l[1]) #prints the second element in the list
print(l[-1]) #what does this print?
[1, 2, 3, 4]
1
2
4
#list slicing. very useful way in python to access sub-lists in python
#say we want to make a list that only has the elements between positions 2 and 4 in list l
sliced = l[2:4]
print(sliced)
#now say we want a list that contains everything but the first number in l
everything_but_first = l[1:]
print(everything_but_first)
#now make a list that has everything except the last element in the list (remember the -1 index)
everything_but_last = l[:-1]
print(everything_but_last)
[3, 4]
[2, 3, 4]
[1, 2, 3]
#we can modify the values in the list
l[1] = 3000
print(l[1])
3000
#we can add values to the end of the list with the append() function
print("adding a value")
l.append("hi!")
print(l)
adding a value
[1, 3000, 3, 4, 'hi!']
Tuples
Tuples are like lists, but they are less flexible. Unlike lists, they have a fixed size, and you can’t reassign elements to them once they’re assigned. The advantage is that they are more memory efficient than lists. So it’s good to use them when you know that you will not be changing your data around much.
#declare a tuple. use round brackets instead of square brackets
person = ('Martin', 50, 1.65)
print(person)
#you can still access its elements just like in a list
print(person[1])
('Martin', 50, 1.65)
50
Dictionaries
Dictionaries are one of the most useful data structures in Python and because they are very powerful for organizing data. A dictionary is like a list, except every element is indexed by a ‘key instead of a number like we saw with lists and tuples.
d[key] = value
# dictionaries are initialized with curly braces
d = {} # is an empty dictionary
#let's add some keys to the dictionary and give it a value.
d['heights'] = []
d['weights'] = []
print(d)
{'heights': [], 'weights': []}
#now we can add 'heights' to the list
d['heights'].append(165.4)
d['weights'].append(221.2)
print(d)
#if we want to get the 'keys' of the dictionary we use the keys() function
print(d.keys())
{'heights': [165.4], 'weights': [221.2]}
dict_keys(['heights', 'weights'])
Python is very flexible with data
As you may have started to notice, it is possible to store any kind of mixture of data into lists, tuples, and dictionaries. Here are some examples:
mix = ['hi', 1, 2, ('a', 2, 'e')]
print(mix)
d2 = {1: [1, 2, 3], 'bob': 4}
print(d2)
['hi', 1, 2, ('a', 2, 'e')]
{1: [1, 2, 3], 'bob': 4}
Operations
Now that we have an idea of how Python stores data, we would like to be able to do something interesting with is. That is, peform operations on the data in an efficient manner.
for loops
Loops make python repeat a set of commands a given number of times. They are by far the most widely used loop.
# for loops store the each item in the list in the variable following the 'for' one at a time.
#let's iterate through that 'mix' list that we made in the previous cell and print each item in the list
for i in mix:
print(i)
hi
1
2
('a', 2, 'e')
# we can also iterate through a range of numbers by using the range(n) command which returns a list containing the
# integers within the specified range
for i in range(10):
print(i)
0
1
2
3
4
5
6
7
8
9
#write a for loop that adds the numbers from 1 to n. declare any variables you may need
n = 4
total = 0
#the loop will repeat whatever is under it and indented to the right
for i in range(n):
total = total + i
print(total)
6
if statements
if statements allow us to control which parts of code are executed depending on a condition. This condition is expressed as a boolean that can be True or False. If the statement is True then the code contained in the if statement will execute. Otherwise, it gets skipped.
#first, a bit more about booleans. we can compare two booleans using the '==' operator to obtain a 'True' if they are
# equal and 'False' if they are not equal.
print(True == True)
print(True == False)
True
False
# We can perform some operations on boolean variables to better express conditions
#the 'and' operation gives a True boolean if both elements are true
a,b = True, True
print(a and b)
a,b = True, False
print(a and b)
# the 'or' operator gives True if either one (or both) of the elements is true
print(a or b)
# the 'not' operator simply gives you the opposite of the given element
print(not a)
True
False
True
False
feel_like_it = True
raining = False
date_tonight = True
#write a boolean to decide if you should go to the gym based on the three booleans above.
go_to_gym = (feel_like_it and not raining) or date_tonight
print(go_to_gym)
#play around with different values of the variables!
True
We can use if statements to make our loops more powerful
#write a for loop that prints every even number up until n. (hint. use the modulo operator which returns the
# remainder of dividing two numbers. e.g. 5 % 2 = 3, 10%2 = 0)
n = 25
for i in range(n):
if i % 2 == 0:
print(i)
else:
continue #the 'continue' statement lets you skip to the next iteration in the loop
Now we can use these booleans to control how our code gets executed. Here’s an example:
if feel_like_it and raining: #whatever follows the if has to be a boolean statement
print("i feel like it, but it's raining")
#if the previous clause is not met, the 'elif' or 'else if' block is checked
elif date_tonight:
print("i have a date tonight"
#if neither the if or the elif match then we go into the 'else'
else:
print("i should just stay home")
i have a date tonight
Try an example for yourself. This is a famous programming challenge to test if statements, known as the ‘fizzbuzz’ test. You have to print the numbers from 0 to 50 following three rules:
- If the number is divisible by 3, print ‘fizz’
- If the number is divisible by 5, print ‘buzz’
- If the number is divisible by both 3 and 5, pring ‘fizzbuzz’
- Otherwise, print the number.
There are many different ways to do this, so take a couple of minutes to come up with yours. (hint. use the % operator).
for i in range(100):
if i % 15 == 0:
print("fizzbuzz")
elif i % 3 == 0:
print("fizz")
elif i % 5 == 0:
print("buzz")
else:
print(i)
fizzbuzz
1
2
fizz
4
buzz
fizz
7
8
fizz
buzz
11
fizz
13
14
fizzbuzz
16
17
fizz
19
buzz
fizz
22
23
fizz
buzz
26
fizz
28
29
fizzbuzz
31
32
fizz
34
buzz
fizz
37
38
fizz
buzz
41
fizz
43
44
fizzbuzz
46
47
fizz
49
buzz
fizz
52
53
fizz
buzz
56
fizz
58
59
fizzbuzz
61
62
fizz
64
buzz
fizz
67
68
fizz
buzz
71
fizz
73
74
fizzbuzz
76
77
fizz
79
buzz
fizz
82
83
fizz
buzz
86
fizz
88
89
fizzbuzz
91
92
fizz
94
buzz
fizz
97
98
fizz
List comprehensions
List comprehensions are a very nice Python feature that allow you to make lists in a single line. Let’s see how they work.
# this will grow a list where each element in the list is whatever the statement preceding the 'for' evaluates to
numbers_times_two = [n*2 for n in range(10)]
print(numbers_time_two)
# we can also add if statements in the list comprehension
odd_numbers = [i for i in range(10) if i % 2 != 0]
print(odd_numbers)
#now try one yourself. make a list comprehension where each item is a tuple (number, number*number)
square_tuples = [(i, i*i) for i in range(10)]
Functions
That day of the week function was super useful! Let’s say we want to use that code again many times, but sometimes we want it to find a different day of the week. We would have to change our if statement each time and re-run the code. This seems like a bit of a pain. Thankfully there is a better way.. functions! Think of a function as a little machine that takes in some input and does something to it and returns some output. So let’s turn the days of the week finder into a function.
#the first line of every function is a header. headers have 3 parts. the 'def' keyword which tells python you are
#about to declare a function, then the name of the function, and finally the inputs to the function
def day_finder(day_to_find):
days_of_week = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Satuday', 'Sunday']
for day in days_of_week:
if day == day_to_find:
#the return statement ends every function and it 'sends' the output of your function to whoever called it
return "Thank God it's %s." % (day) # the %s in the string is like a placeholder that gets filled with
# the value of the string variable 'day'
else:
continue
#you can call any function just by typing its name and the arguments you want it to work on in braces ()
print(day_finder('Tuesday')) #"thank god it's tuesday" is the return value of the function day_finder()
Thank God it's Tuesday
A word on ‘variable scope’
As you may have noticed, it would be a mess if variables were accessible from everywhere in the code. In fact, in Python, anything that is defined within an ‘indentation block’ is shared but not otherwise.
Example:
a = 3
def fun():
b = 3
for i in range(10):
i = i + 1
In this example a can be accessed from anywhere in the code. b can only be seen inside the indentation block started by fun() and i can only be seen within the indentation block defined by the for loop.
Object Oriented Programming
Just how we generalized a piece of code that runs on similar kinds of input and gave it a name with the functions example, we can do the same thing with just about any piece of Python. Objects let us easily work with instances of some kind of thing where each instance might be a little different from the other but still behave according to its type of thing.
Let’s illustrate this with our thing being a Recipe. We can have many different types of recipes but we would like to be able to deal with each one in a uniform manner. We therefore define a Recipe as an object that is defined by some ‘attributes’
# every object is defined in a 'class' and classes are declared with the 'class' keyword
class Recipe:
def __init__(self, n, ig, ml, pt):
self.name = n
self.ingredients = ig #set the ingredients attribute of the object to the value of ig
self.meal = ml
self.prep_time = pt
#now that we've defined what a Recipe should look like, we can nicely store some new recipes.
#let's make some recipes
sandwich = Recipe('sandwich', ['ham', 'bread', 'cheese'], 'lunch', 10)
cake = Recipe('cake', ['flour', 'sugar', 'eggs'], 'dessert', 90)
#add two more recipes of your own!
# now we can very conveniently access some information about our recipes by name. This can be done with the '.'
# operator that we saw above
#print the ingredients in the sandwich, and the preparation time of the cake
print(sandwich.ingredients)
print(cake.prep_time)
['ham', 'bread', 'cheese']
90
Let’s go even further and make a new object to contain our Recipe objects. Let’s call this class Cookbook and it will simply contain a list of Recipe objects. However, it will not only have some data variables, but it will also be able to perform functions.
class Cookbook:
def __init__(self, r):
self.recipes = r
#functions declared inside a class are called 'Class functions' and they act on an object
def get_vegetarian(self):
"""This function is going to return recipes in the cookbook that do not contain meat."""
meats = ['ham', 'beef', 'chicken', 'fish']
veg_dishes = []
for recipe in self.recipes: #the 'self' keyword is used to access the object the function is being called on
if meats not in recipe.ingredients: #hint: use the 'in' operator which returns true if a value is in the
#given list. e.g.: 5 in [1, 3, 5] returns True.
veg_dishes.append(recipe)
return veg_dishes
#write a class function that returns a list of recipes that take under 'n' minutes to prepare
def preptime(self, n):
recipes = []
for recipe in self.recipes:
if recipe.prep_time < n:
recipes.append(recipe)
return recipes
# let's make a cookbook
#gather some recipes
recipes = []
recipes.append(Recipe('steak', ['beef', 'butter', 'mashed potatoes'], 'main', 120))
recipes.append(Recipe('toast', ['nutella', 'bread'], 'snack', 5))
recipes.append(Recipe('salad', ['lettuce', 'kale', 'tomatoes'], 'main', 15))
recipes.append(Recipe('chicken parm', ['chicken', 'sauce', 'cheese'], 'main', 90))
recipes.append(Recipe('brownie', ['chocolate', 'flour', 'eggs'], 'dessert', 15))
#put them in a cookbook
cookbook = Cookbook(recipes)
#get vegetarian recipes
print(cookbook.get_vegetarian())
#get recipes that take less than 20 minutes to prepare
print(cookbook.preptime(20))
[<__main__.Recipe object at 0x1048ac208>, <__main__.Recipe object at 0x1048ac748>, <__main__.Recipe object at 0x1048ac278>, <__main__.Recipe object at 0x1048ac780>, <__main__.Recipe object at 0x1048ac7b8>]
[<__main__.Recipe object at 0x1048ac748>, <__main__.Recipe object at 0x1048ac278>, <__main__.Recipe object at 0x1048ac7b8>]
#oops what is that? because our functions are returning lists of objects we are seeing how the objects are represented
# when we print them. What you see are addresses in memory where the objects are stored. Let's print it in a way
# we can understand
#print the name and ingredients of recipes that take under 20 minutes to prepare
short_recipes = cookbook.preptime(20)
for s in short_recipes:
print(s.name)
toast
salad
brownie
Libraries
We’ve now covered most of the basics you need to get up and running. However, one of the nicest things about Python is that it has a fairly extensive ‘standard library’. The standard library is a set of functions that come with Python that do a variety of useful things so that you don’t have to reinvent the wheel each time you write a program. We’ve already seen an example with the range() function. I’m going to give some examples of some of the most useful functions in the standard library, but you should always check if what you are trying to do has already been implemented to save you time.
Some functions are directly built-in and some you have to import from a module which is just the name of a Python program whose functions you can use in your code.
Help
#help prints what the given function does
help(abs)
Help on built-in function abs in module builtins:
abs(x, /)
Return the absolute value of the argument.
Sets and Lists
#a set is a group of unique items from a list
pop_stars = ["beyonce", "rihanna", "lady gaga", "lady gaga"]
hip_hop_stars = ["rihanna", "nicki minaj", "lil kim"]
pop = set(pop_stars)
hip_hop = set(hip_hop_stars)
print(pop, hip_hop)
#you can perform some set operations. look up the Python set documentation an print the intersection between both sets.
overlap = pop.intersection(hip_hop)
print(overlap)
{'beyonce', 'lady gaga', 'rihanna'} {'lil kim', 'nicki minaj', 'rihanna'}
{'rihanna'}
#sort a list
s = sorted([1, 5, 3, 2])
print(s)
#max and min of a list
print(max(s))
print(min(s))
#print the sum of a list's elements
print(sum(s))
#get length of list
print(len(s))
[1, 2, 3, 5]
5
1
11
4
#write a for loop that iterates through each *index* in s and prints the index
for i in range(len(s)):
print(i)
#the enumerate() function gives you the item and the index of a list at the same time
for i, number in enumerate(hip_hop_stars):
print(i, number)
0 rihanna
1 nicki minaj
2 lil kim
Some math
#let's import some libraries so we can use their functions
import math
import random
#python numerical tools
import numpy as np
#generate a random floating point number between 0 and 1
ran = random.random()
print(ran)
#print a random integer in the given range
random_integer = random.randint(2, 100)
print(random_integer)
#sample randomly from a list
print(np.random.choice(["watermelon", "mango", "pineapple"]))
0.30930068420811463
6
pineapple
#compute e^(n)
print(math.exp(10))
#compute x^n
print(math.pow(2,3))
22026.465794806718
8.0
String functions
# you can remove characters from the end of a string with the strip() function
disney = "I'm Walt Disney."
print(disney.strip(".")) #removes the character from the given string
#the join function inserts characters between elements in a list and joins them into a string
print("-".join(disney))
#the opposite of join is the split() function which breaks a string up into a list of sub-strings
print(disney.split()) #you can also tell split() which characters to break on
I'm Walt Disney
I-'-m- -W-a-l-t- -D-i-s-n-e-y-.
["I'm", 'Walt', 'Disney.']
File handling
A very important part of dealing with scientific data is handling files containing your data and loading them into your Python scripts. Thankfully Python also makes this very easy.
#to open a file you just use the open() function along with the 'with' context manager (more on this below)
#the 'with' block takes care of opening and closing the file, and giving us the lines of the file to iterate over
with open("food.csv", "r") as food: # the "r" argument tells open() that we want to read the file
for item in food:
print(item.strip("\n")) #let's get rid of the linebreak character
food_item, price, quantity
bananas, 1.5, 10
cupcakes, 3, 4
skittles, 2, 200
tacos, 2, 100
chips, 1, 2.5
#we can also write to a file
with open("helloworld.txt", "w+") as hello:
hello.write("Hello, world!")
#check to see if the file was created
Multiprocessing
Most computers today have multiple processors, meaning you can use these processors simulaneously to make your computations go a lot faster. Default python code is run as a single process. So if you have some work to do that can be split up into independent parts, you can easily implement this with the multiprocessing module in Python.
import multiprocessing
import time #this module allows us to do some operations involving time.
MAX_PROC = 4
def square(x):
time.sleep(3) #let's make it a bit slower by making python sleep for 10 seconds before returning the output
return x*x
to_do = [1, 2, 3, 4, 5, 6, 7, 8]
#let's write a loop that squares each element in that list in series
#record the time at which we start the computation
t_start_serial = time.time()
squared_serial = []
for i in to_do:
squared.append(square(i))
#get the difference in time between now and the start time to get total time.
t_end_serial = time.time() - t_start_serial
print("Serial job took %s seconds." % (t_end_serial))
print(squared_serial)
Serial job took 24.022435903549194 seconds.
[]
#that was slow! now let's do this in parallel
pool = multiprocessing.Pool(MAX_PROC) #we start a 'pool' of workers that we can send processing jobs to
t_start_para = time.time()
squared_para = []
for squared_number in pool.map(square, to_do):
squared_para.append(squared_number)
t_end_para = time.time() - t_start_para
print("Parallel job took %s seconds!" % (t_end_para))
print(squared_para)
Parallel job took 6.006745100021362 seconds!
[1, 4, 9, 16, 25, 36, 49, 64]
Mini-project
At this point you should have a pretty good idea of the Python basics and some of the extras. Yet, we are still only scratching the surface of the surface of the iceberg. Python has appliations in pretty much every field of programming and software development. But since we are mainly interested in using it as a tool for data handling let’s do a mini data-science project to get an idea of some more data-specific Python capabilities. Here the goal is to be able to load a data-set efficiently and do some nice visualizations.
The mini project is to take baby name data from the US social security database and try to identify “Hipster” names. This example inspired by a Kaggle post (https://www.kaggle.com/ryanburge/d/kaggle/us-baby-names/hipster-names). You can load the original dataset here.
I filtered and re-arranged the original data to make it easier for us to handle (but trust, me I used Python for that and it was very easy). So you can find the dataset we will use in this exercise in the workshop downloads under the name BabyNames.csv
Here’s what the data looks like:
name, 1880, 1881, 1882, .... , 2014
Aaron, 3, 4, 6, 22, 0, ...., 199
Aaliyah, 0, 0, 0, 0, 1, ...., 100
As you can see, each row in the file is a baby name, and each column contains the number of babies with that name for each year this dataset was collected.
import os
#this is python's main plotting library
import matplotlib.pyplot as plt
#tell the notebook to make plots appear inline
%matplotlib inline
#set the size of figures
plt.rcParams['figure.figsize'] = 12, 10
/Users/carlosgonzalezoliver/anaconda/envs/py35/lib/python3.5/site-packages/PIL/Image.py:85: RuntimeWarning: The _imaging extension was built for another version of Pillow or PIL
warnings.warn(str(v), RuntimeWarning)
/Users/carlosgonzalezoliver/anaconda/envs/py35/lib/python3.5/site-packages/PIL/Image.py:85: RuntimeWarning: The _imaging extension was built for another version of Pillow or PIL
warnings.warn(str(v), RuntimeWarning)
#the os module lets us take care of operating system operations. let's use it to specify the path to a file for opening
#let's load the name dataset
babypath = os.path.join("/", "Users", "carlosgonzalezoliver", "Projects", "Notebooks", \
"BabyNames.csv")
def read_names(file_path):
names_dict = {}
with open(file_path) as f:
for row_number, row_string in enumerate(f):
#first we need to check if we're at a header row
if row_number == 0:
#let's store the years so we can use them as labels later
#we split the row_string by the comma since this is a csv file
years = row_string.split(",")[1:]
#convert each year to an integer
int_years = [int(y.strip()) for y in years]
else:
row_info = row_string.split(",")
name = row_info[0]
counts = [float(c.strip()) for c in row_info[1:]]
names_dict[name] = counts
#return a dictionary with all the names and their data, and a list with the years
return names_dict, int_years
baby_dict, year_list = read_names(babypath)
#look up your name in the dictionary!
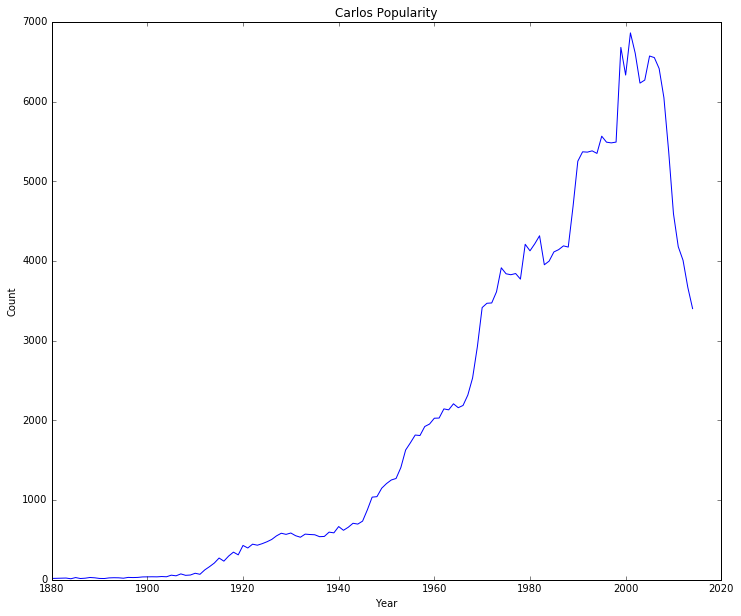
print(baby_dict['Carlos'])
[17.0, 19.0, 20.0, 22.0, 13.0, 28.0, 16.0, 20.0, 29.0, 25.0, 17.0, 16.0, 24.0, 26.0, 25.0, 20.0, 30.0, 28.0, 30.0, 36.0, 37.0, 38.0, 37.0, 41.0, 38.0, 58.0, 50.0, 74.0, 56.0, 60.0, 82.0, 69.0, 124.0, 165.0, 210.0, 273.0, 234.0, 298.0, 347.0, 313.0, 431.0, 399.0, 447.0, 434.0, 453.0, 477.0, 506.0, 551.0, 584.0, 570.0, 587.0, 553.0, 534.0, 573.0, 568.0, 565.0, 541.0, 544.0, 598.0, 589.0, 668.0, 621.0, 659.0, 709.0, 699.0, 736.0, 878.0, 1037.0, 1043.0, 1149.0, 1207.0, 1252.0, 1271.0, 1408.0, 1628.0, 1719.0, 1816.0, 1810.0, 1923.0, 1954.0, 2027.0, 2029.0, 2144.0, 2132.0, 2208.0, 2159.0, 2187.0, 2317.0, 2532.0, 2925.0, 3415.0, 3469.0, 3473.0, 3613.0, 3914.0, 3839.0, 3827.0, 3842.0, 3772.0, 4209.0, 4127.0, 4215.0, 4316.0, 3952.0, 3998.0, 4113.0, 4142.0, 4189.0, 4174.0, 4682.0, 5251.0, 5369.0, 5365.0, 5381.0, 5349.0, 5565.0, 5490.0, 5481.0, 5491.0, 6679.0, 6332.0, 6861.0, 6606.0, 6231.0, 6269.0, 6571.0, 6551.0, 6414.0, 6048.0, 5371.0, 4592.0, 4179.0, 4008.0, 3668.0, 3402.0]
#first let's look for an individual name and plot its popularity trend in time.
#this function takes as input a name to search for, and the dataframe. it will return a list of years that name
# appears in, and a list of the counts for each of those years
#one obstacle for this task is that some names have multiple counts for the same year. so we will have to deal with
# this. we'll take the average of the years and use that as our count.
#notice the 'title=' argument. this is known as keyword argument. it is useful for giving a default value to a function
#so in this case the user can decide whether or not he gives the title of the plot. If he/she doesn't then the title
#defaults to "Plot Title"
def name_plot(name, names_dict, year_list, title="Plot Title"):
#we give the matplotlib function plot() the x and y lists that we would like to plot
plt.plot(year_list, baby_dict[name], label=name)
plt.title(title)
plt.xlabel("Year")
plt.ylabel("Count")
pass
#let's try out the function. give it a name and the names_df
name_plot("Carlos", baby_dict, year_list, title="Carlos Popularity")
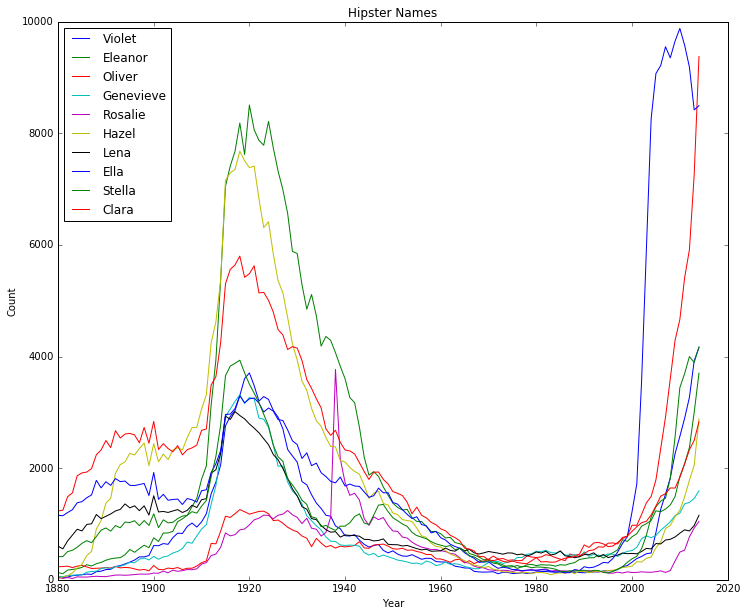
# we define a hipster name with the three following criteria. let's say a name is popular if it reaches 1000 babies in
# a given year.
# Criteria:
# * was very popular a long time ago (at least 1000 count between 1915-1930)
# * very unpopular 30 years ago (under 1000 between 1980-2000)
# * popular in recent years (more than 1000 after 2010)
def hipster_names(baby_dict, year_list):
#let's start an emty list to contain all the matching 'hip' names
hip_names = []
#let's establish the ranges of time to look at
popular_range = range(1915, 1930)
unpopular_range = range(1960, 2000)
recent = 2010
names = baby_dict.keys()
#we go through each row in the name group
for name in names:
#set some booleans with some initial values that will tell us together if the name is hip
was_popular = False
was_unpopular = True
becoming_popular = False
#we go through each year in the name
for index, count in enumerate(baby_dict[name]):
current_year = year_list[index]
#check if the name was popular a long time ago
if current_year in popular_range and count >= 1000:
was_popular = True
continue
#check if the year was unpopular recently
if current_year in unpopular_range and count >= 1000:
was_unpopular = False
continue
#check if the name is growing in popularity
if current_year >= recent and count >= 1000:
becoming_popular = True
continue
#combine all the booleans to tell us if the name matches all our criteria. if it does, add it to the list
if was_popular and was_unpopular and becoming_popular:
print(name)
hip_names.append(name)
#return the list.
return hip_names
#now we just have to call the function hipster_names. give this a couple of minutes as it's a lot of data!
hip_names = hipster_names(baby_dict, year_list)
print(hip_names)
Violet
Eleanor
Oliver
Genevieve
Rosalie
Hazel
Lena
Ella
Stella
Clara
['Violet', 'Eleanor', 'Oliver', 'Genevieve', 'Rosalie', 'Hazel', 'Lena', 'Ella', 'Stella', 'Clara']
#let's plot the trendlines of each hip name
for n in hip_names:
name_plot(n, baby_dict, year_list, title="Hipster Names")
#we set the legend, x-axis label, y-axis label, and title of the plot
plt.legend(loc="upper left")
<matplotlib.legend.Legend at 0x10d93a748>
Things we didn’t cover
There are many, many, many more useful libraries that I didn’t have time to cover. I’m going to list a few of the ones that you might want to check out.
- numpy very powerful numerical and matrix operations
- pandas game changer for data handling
- seaborn scientific plotting
- scikit-learn very complete Machine Learning algorithms and tools
- BioPython biological sequence data and analysis. (alignments, trees, etc.)